¿Qué es Hadoop? Hadoop es un framework de software de código abierto que se utiliza para procesar grandes conjuntos de datos. Está diseñado para escalar desde un único servidor hasta miles de máquinas con miles de terabytes de datos. Utiliza una arquitectura distribuida para procesar grandes conjuntos de datos usando un sistema de archivo distribuido. Está diseñado para funcionar en entornos económicos y de bajo costo, permitiendo a los usuarios almacenar y procesar enormes cantidades de datos. Hadoop está compuesto por varios componentes, incluyendo el sistema de archivos distribuido HDFS, el sistema de administración de trabajos MapReduce y la biblioteca de herramientas de procesamiento de datos Hadoop. Estos componentes se pueden utilizar juntos para procesar y analizar grandes conjuntos de datos.
Introducción a Hadoop
¿Qué es Hadoop? Hadoop es una plataforma de código abierto que permite la distribución de aplicaciones de procesamiento de datos y el almacenamiento de grandes cantidades de datos en cluster de servidores. Está diseñado para escalar desde un solo servidor hasta cientos de máquinas, cada una ofreciendo almacenamiento y procesamiento de datos.
Introducción a Hadoop Hadoop es una herramienta de software de código abierto que permite el procesamiento de grandes cantidades de datos en un cluster de servidores. La idea detrás de Hadoop es permitir que una gran cantidad de servidores se conecten para compartir tareas, procesar datos y almacenar información. Esta herramienta ha permitido que se procesen grandes cantidades de datos de forma rápida y eficiente.
Hadoop incluye tres componentes principales: el HDFS (Hadoop Distributed File System), el MapReduce y el YARN (Yet Another Resource Negotiator). El HDFS es un sistema de archivos distribuido que permite almacenar grandes cantidades de datos en una red de computadoras. MapReduce es una herramienta de programación que permite procesar grandes cantidades de datos de forma paralela. YARN es un sistema de administración de recursos para gestionar la capacidad computacional de una red.
Hadoop se usa principalmente para procesar datos masivos y realizar análisis de datos. También se puede usar para aplicaciones de Machine Learning, así como para el desarrollo de aplicaciones de Big Data. Esta herramienta se ha convertido en una de las principales herramientas para el análisis de datos en la actualidad.
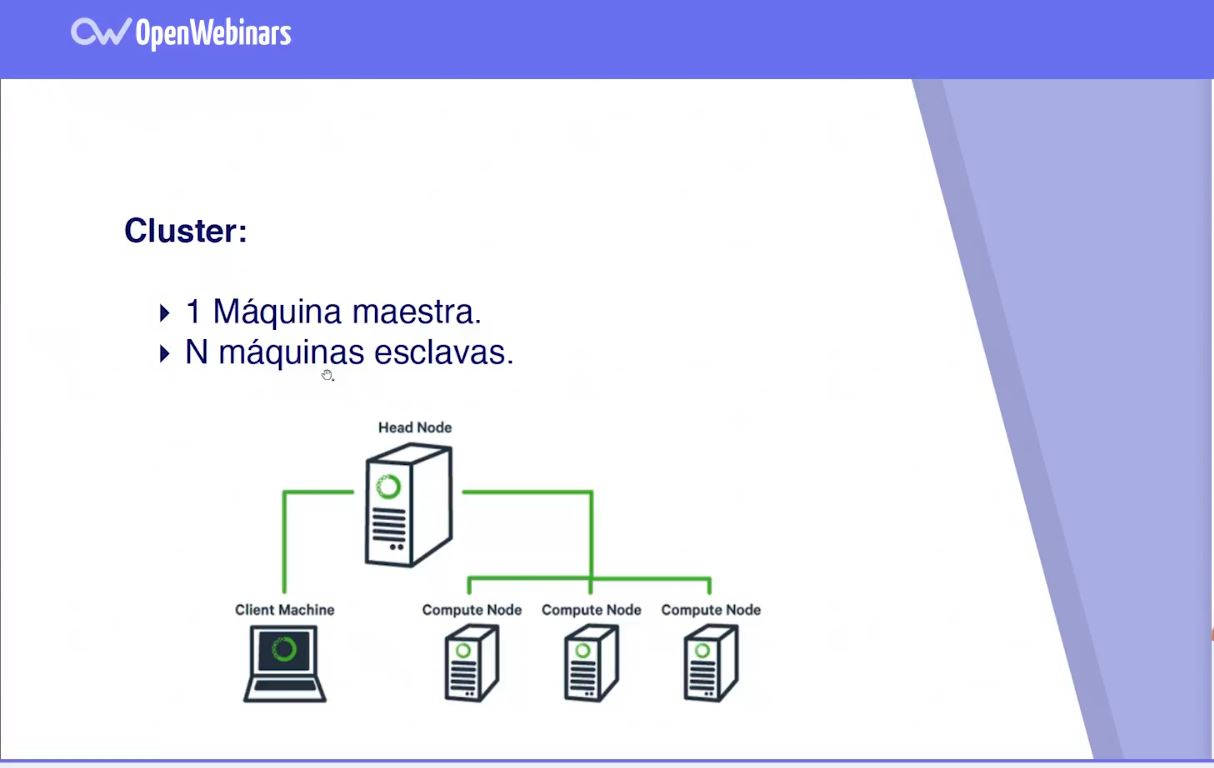
¿Qué constituye un clúster de Hadoop?
¿Qué es Hadoop?
Hadoop es una plataforma de código abierto para procesamiento de datos masivos distribuidos. Está diseñado para escalar desde una sola computadora a miles de máquinas, proporcionando un almacenamiento de datos y procesamiento de computación de alta velocidad y de bajo costo. Está basada en proyectos de código abierto Apache como HDFS, MapReduce, HBase, Hive, Pig y otros.
¿Qué constituye un clúster de Hadoop?
Un clúster de Hadoop es un grupo de servidores conectados entre sí para procesar grandes volúmenes de datos. Estos clústeres de servidores se conectan a través de una red de computadoras para formar una sola gran unidad y proporcionar almacenamiento y procesamiento de datos de forma distribuida. Estas instalaciones se utilizan para almacenar y procesar grandes volúmenes de datos que van desde gigabytes a petabytes y terabytes. El clúster de Hadoop está compuesto de varios nodos de computación, uno o más nodos de almacenamiento y un nodo maestro. El nodo maestro se encarga de controlar todas las operaciones que se realizan en el clúster. Los nodos de computación, por otro lado, se encargan de procesar los datos y realizar las tareas asignadas por el nodo maestro. Los nodos de almacenamiento se utilizan para almacenar los datos. El clúster de Hadoop también incluye herramientas que aseguran el control, el monitoreo y el mantenimiento del clúster.
Arquitectura del ecosistema Hadoop
¿Qué es Hadoop? Hadoop es un framework de código abierto para almacenamiento y procesamiento de grandes cantidades de datos distribuidos a través de una red de servidores de computación. Esto significa que, en lugar de procesar los datos en un solo servidor, Hadoop distribuye los datos entre los servidores para un procesamiento más rápido. Esta distribución de los datos en diferentes servidores se conoce como clúster.
Arquitectura del ecosistema Hadoop El ecosistema Hadoop está compuesto por cinco componentes principales: HDFS (Hadoop Distributed File System), YARN (Yet Another Resource Negotiator), MapReduce, Hadoop Common y Ambari.
HDFS es el sistema de archivos distribuido de Hadoop, utilizado para almacenar grandes cantidades de datos en un clúster. Está diseñado para almacenar grandes cantidades de datos de forma segura y escalable, permitiendo a los usuarios la lectura y escritura de los mismos.
YARN es el administrador de recursos de Hadoop. Su función es gestionar el uso de los recursos del clúster, asignando los recursos a los diferentes procesos de MapReduce.
MapReduce es un modelo de programación para procesar grandes cantidades de datos en un clúster de computadoras. Está diseñado para permitir a los usuarios procesar enormes cantidades de datos de manera rápida y eficiente.
Hadoop Common es un conjunto de herramientas y bibliotecas que se utilizan para simplificar el desarrollo de aplicaciones de Hadoop. Estas herramientas y bibliotecas facilitan la escritura, ejecución y administración de procesos MapReduce.
Ambari es una herramienta de administración de clúster para Hadoop diseñada para simplificar la configuración, administración y monitorización de un clúster de Hadoop. Ambari también proporciona una interfaz web para que los usuarios administren y monitoricen el clúster de Hadoop.
1) CERDO Apache
¿Qué es Hadoop? Hadoop es un software de código abierto que permite a los usuarios almacenar grandes cantidades de datos y procesarlos en paralelo a través de una red de servidores. El sistema de almacenamiento de Hadoop se conoce como HDFS (Hadoop Distributed File System) y se compone de dos componentes principales: el sistema de almacenamiento y el procesamiento. El procesamiento se realiza a través de una plataforma de computación distribuida conocida como MapReduce.
Cerdo Apache es una herramienta de procesamiento de datos para Apache Hadoop que permite a los usuarios escribir fácilmente programas de análisis de datos en lenguajes similares a SQL. Permite a los usuarios combinar scripts de Pig Latin con scripts de Java y procesar grandes volúmenes de datos de forma mucho más rápida y eficiente. Además, ofrece una variedad de funciones útiles para el análisis de datos, como filtros, agrupaciones, uniones y agregaciones.
2) base de Apache
Apache Hadoop es un marco de software de código abierto para almacenar y procesar grandes conjuntos de datos distribuidos en clústeres de computadoras. Está compuesto por dos principales componentes: la base de Apache Hadoop (HDFS) y el motor de procesamiento MapReduce. HDFS es un sistema de archivos distribuido y escalable que le permite almacenar grandes cantidades de datos en una variedad de nodos de computadoras. MapReduce es un motor de procesamiento paralelo que permite a los usuarios procesar grandes conjuntos de datos de forma eficiente. Al combinar estos dos componentes, Hadoop proporciona una plataforma potente para el almacenamiento y procesamiento de grandes cantidades de datos.
Hadoop es ampliamente utilizado en entornos empresariales para la gestión de grandes cantidades de datos. Esto incluye la gestión de grandes volúmenes de datos de transacciones, análisis de datos, almacenamiento de datos en la nube, análisis predictivo, análisis de texto, aprendizaje automático y procesamiento de imágenes.
Mientras que los usuarios de Hadoop pueden beneficiarse de la escalabilidad y la flexibilidad de la plataforma, los desarrolladores de Hadoop pueden aprovechar las herramientas y APIs proporcionadas por Apache para crear aplicaciones para procesar grandes conjuntos de datos.
3) Colmena Apache
Apache Hadoop es un conjunto de herramientas de software de código abierto para el almacenamiento y procesamiento de datos distribuidos, diseñado para escalar a miles de nodos en un clúster. Está compuesto por Colmena Apache, una plataforma de análisis de datos basada en Hadoop, diseñada para simplificar la extracción de información de los datos almacenados en Hadoop. Colmena Apache ofrece una herramienta de consultas SQL estándar para consultar los datos almacenados en Hadoop, lo que facilita el análisis de datos y la exploración de datos. Colmena Apache también permite a los usuarios crear sus propios scripts en lenguajes de programación como Apache Pig, Apache Hive y Apache Spark. Esto permite a los usuarios desarrollar aplicaciones de análisis de datos que se ejecutan en un clúster Hadoop para realizar tareas como el análisis de datos, la minería de datos, el procesamiento de transacciones en línea, etc.
4) cuchara apache
Hadoop es un proyecto de código abierto de Apache Software Foundation, que se utiliza para almacenar y procesar grandes cantidades de datos de forma distribuida y escalable. A menudo se conoce como la «cuchara Apache», ya que se compone de varias herramientas y tecnologías relacionadas, como MapReduce, HDFS, HBase, Spark, Hive y Pig. Estas herramientas se utilizan para proporcionar una solución de almacenamiento y procesamiento de datos segura y de alto rendimiento. También se puede utilizar para procesar diferentes tipos de datos, como datos estructurados, semi-estructurados y no estructurados. Hadoop se utiliza ampliamente en entornos de Big Data, ya que es una forma eficaz de administrar y procesar grandes cantidades de datos.
5) Canal Apache
¿Qué es Hadoop? Hadoop es un marco de código abierto para el procesamiento distribuido de datos en un clusters de computadoras. Está diseñado para escalar de una computadora a miles de máquinas, proporcionando un almacenamiento y procesamiento de datos rápido y confiable.
Canal Apache Apache Hadoop es una colección de herramientas de software de código abierto para el almacenamiento y procesamiento de grandes cantidades de datos. Está formado por Apache Hadoop Core y Apache Hadoop YARN. Apache Hadoop Core es el núcleo de Hadoop, que incluye un sistema de archivos distribuido (HDFS), un motor de ejecución distribuida (MapReduce) y una biblioteca de herramientas de programación para el procesamiento de datos en paralelo (Pig). Apache Hadoop YARN es el gestor de recursos para ejecutar aplicaciones en una infraestructura Hadoop. Proporciona una infraestructura para la ejecución de aplicaciones y el uso compartido de recursos entre ellas.
6) Guardián del zoológico de Apache
Hadoop es una plataforma de software de código abierto para la computación distribuida de datos a gran escala en clusters de computadoras. Está diseñado para escalar de una manera sencilla desde una única máquina a cientos de máquinas, procesando cientos de terabytes de datos. Hadoop es uno de los componentes principales del proyecto Apache ZooKeeper, que es una herramienta para administrar grandes conjuntos de servidores en un entorno distribuido. El ZooKeeper es un servidor de administración de configuración que se encarga de guardar y distribuir la configuración de una aplicación entre múltiples servidores. Esto le permite a los desarrolladores crear aplicaciones escalables que se ajustan a un entorno distribuido. El ZooKeeper es especialmente útil para aplicaciones que utilizan Hadoop, ya que le permite al administrador de configuración mantener una copia de seguridad de todos los servidores Hadoop en caso de que alguno de ellos falle. Por lo tanto, el ZooKeeper es el guardián del zoológico de Apache Hadoop.

Manex Garaio Mendizabal es un ingeniero de sistemas originario de España, conocido por ser el creador de la popular página web «Sapping». Nacido en 1985, Manex comenzó su carrera en el campo de la tecnología como desarrollador de software en una empresa local. Después de varios años de experiencia en la industria, decidió emprender su propio proyecto y así nació «Sapping». La página web se ha convertido en un referente en el mundo de la tecnología y ha sido utilizada por miles de personas alrededor del mundo. Gracias